Google Summer of Code '24 @ Apache NuttX Final Report
TL;DR: NO! No shortcuts, it's worth it I promise.
Hi, I am Saurav Pal. I was a Google Summer of Code (GSoC) '24 contributor to the Apache NuttX Real Time Operating System (RTOS), working on designing and implementing mnemofs, a file system for NAND flashes, aiming at enabling file system support for the NAND flashes in the Apache NuttX RTOS.
I'll be taking you through my entire work. Prerequisites you ask? None. Actually, you just need to know English. I'll be explaining everything else.
Storage devices
A lot of storage devices are available like floppy disks. Ok, probably not the best example as some readers may not even have seen floppy disks in their lives. Compact Disks (CDs), Hard Disk Drives (HDDs), and Solid State Drives (SDDs) are some more popular and slightly more recent mediums of storage. NAND flashes are one such storage device.
When we talk about storage devices, we mean non-volatile memory. This means that the stored data is persistent even when power is no longer being provided to the storage device. Random Access Memory (RAM) is the standard example of a volatile memory medium, which loses all data once it loses power. Some common storage devices for embedded systems include: EPROM, EEPROM, NOR Flash and NAND Flash. NAND flashes and NOR flashes are very close competitiors, and are very often selected to be used on embedded system projects when someone doesn't need too much storage.
NAND vs NOR
Now, what are NAND gates or NOR gates?Good question, because it's something you're not required to know for this report.
What are NAND or NOR flashes?Good question, because it's something you're required to know for this report.
NAND and NOR flashes are made out of NAND and NOR gates (like mentioned above, not required to know). Formally, NAND flashes are a type of programmable, non-volatile storage technology built with cells of NAND gates.
Why, where, and which should I use? It's complicated. NAND flashes require less number of lines in their structure and thus are more compact and cheaper than NOR flashes as they require less silicon for the same storage space. Sequential reads are faster in NAND flash, but NAND flashes are slower in random access reads. NOR flashes allow a single machine word (opens in a new tab) to be written to an erased location or read independently. NAND flashes require reads or writes to be in pages, and erases to be in blocks (more on this later). Moreover, NAND flashes are more prone to random bit flipping, and a higher percentage of blocks turn out to be bad blocks right from manufacture, compared to NOR (again, further explanation below).
Structure of NAND flashes
The structure of NAND flashes is very multi-layered for others but simple for us. All we need to know is that a NAND flash is made up of tiny units called blocks, which are themselves made out of tinier units called pages, which further are made up of even tinier units called cells.
While we don't have to think down to the cell level, it's good to know some things about it. In a Single-Level Cell (SLC) NAND flash, each cell is one bit. There are other levels like Multi-Level Cell (MLC) NAND flashes and Triple-Level Cell (TLC) NAND flashes depending on the number of bits per cell.
What we do need to consider are pages and blocks. A block is the smallest erasable unit, while a page is the smallest readable or writeable unit. What is the role of erasable you might ask? Well, if a page was previously written to, it needs to be erased before it can be written again. But since a block is the smallest erasable unit, you'll need to erase the entire block to update a certain page in the block. Another troublesome problem with the erase operation is that on every erase, a block is slightly more worn out than before. Upon repeated erase, it might not be able to reliably store data anymore, which means that it's not guaranteed that the data you read from any page within the block is the data that was written to that page.
The onset of this state of the unreliability of a block means that the block is now a "bad block". However, usage is not the sole cause of bad blocks in NAND flashes. Any good manufacturer tests their products before selling them. In the process of testing a NAND flash, some blocks might be deemed to be unfit for storage right from manufacture itself as they exhibit the unreliability of bad blocks, and are thus also clubbed under bad blocks.
Mentioned above is the tendency for NAND flashes to undergo random bit flipping. What is bit flipping? As the name suggests, the bits might flip sides (pretty treacherous, I know). This is a phenomenon not specific to NAND flashes, and over the years, people have come up with various solutions to deal with this. The solution NAND flashes use is to have some redundant bits to recognize and rectify bit flips, called Error Correction Code (ECC) bits. These parity bits may be stored on the page itself, but a common consensus has come up to keep these bits in a separate area on the page.
Thus, a page is split into two parts: a spare area, and a user data area. The user data area contains, well, the user data. The spare area contains the bits for ECC, even some bit(s) for bad block marking (called a bad block marker), and some other bits. A bad block marker is mostly used by the manufacturer to denote whether a particular block is a bad block.
Virtual File System
What you should know is that Apache NuttX, like most Operating Systems (OSes), has a subsystem (opens in a new tab) called the Virtual File System (VFS). This is technically not a file system itself, but it is tasked with the job of dealing with file systems. What you need to know is that the VFS mandates each file system, that aims to be used as part of an OS, to expose its functionality by following a fixed interface (opens in a new tab). This means that the file system needs to follow some rules regarding what it is expected to do and it needs to follow some expectations of behaviour. This situation can be fully understood using a hypothetical situation I just made up.
Imagine the VFS doesn't exist. You ask your OS to help save the text "hello world" to a file with a name and location of your choice. Now, without any standards of communication or expectations that come with these standards, it might be the case that, depending on which file system you choose, their functionality might range from doing nothing to probably hacking the NSA (opens in a new tab). This is chaos. The OS can't decide which function to call from each FS for your desired task.
To enable this, either the OS needs to know the names of the functions of each file system, or the file systems have to mention the names of the functions that correspond to each functionality that the OS expects a file system to have. We have evolved to agree on the latter, as it puts the burden onto the poor FS developers like me, and also allows you to use file systems that might not be officially included in the OS, but rather, built by some sketchy guy you found on the dark web which you find to be surprisingly the fastest (and which seems to be making a lot of network requests sometimes wink).
Thus, this allows the side effects of a file system operations on the rest of the operating system to be uniform, defined, and predictable (on paper, at the very least) regardless of the file system being used. Thus, the rest of the OS, or even the user, does not need to care about the specifics of the underlying file system, and thus, a VFS enables an OS to be able to support multiple file systems at once. In short, a VFS mandates what the file system does, but not how they do it (this is where file systems differ from each other).
Further, let's say, hypothetically, all FSes could hack the NSA and they each tell the OS the function that will start the hack as required by the VFS. Some day, a new FS is developed by a budding programmer who is not interested in these mundane and boring tasks. What the FS wants to do is launch some of the nuclear missiles that might be owned by your government. Now, this is unusual behaviour for a file system (in this hypothetical world). All file systems have stopped till the line of hacking the NSA. To enable this feature, the OS would need to expand its VFS. The latter part is what happens in the real world as well, though, I can not gaurantee about the former. Any new "feature" expected of file systems needs to be implemented by expanding the VFS. Also, if you can guess, after the expansion of the VFS, both FSes can co-exist. They both implement some features of the VFS, while ignoring others, which is perfectly fine.
Since we're living in happier times, our file systems are content with just managing our storage devices. In fact, since we're talking about standards, POSIX (opens in a new tab) has some of their own guidelines (opens in a new tab) on what a file system is expected to do.
File System Constructs
File systems ultimately help manage storing ones and zeroes onto storage devices to be painless for the user. They abstract away the peculiarities of the underlying electronic storage device, the pain of remembering the location of each bit of data, and many other such things. Over the years, file systems have evolved to agree on some basic concepts (with the help of FOMO (opens in a new tab) of the POSIX and the big-shots OS party). Almost all of these are OS enforced, so, unless your FS wants to do weird gymnastics to circumvent this architecture, it would be great if your FS follows this.
Files and Directories
Some of these constructs are namely files and folders/directories, often collectively called FS objects. You group data belonging to one specific thing as one file, while you arrange multiple files or other directories corresponding to each topic into one directory. It's almost entirely dependent on where you draw the line.
Root and Path
Another of these constructs is the root of a file system and path. Root is the name given to the directory that contains all other files or directories, and is created by all file systems before you even use it. As you can see, this entire directory and file relationship gives rise to a tree-like structure (opens in a new tab). Since a file can not have files inside it (that's the job of a directory), the leaf nodes of the tree might be either files or empty directories. Further, the internal nodes of the tree will be directories, with the root node of the tree being the root of the file system, hence the name.
Let's say, the root has a directory inside it with the name "hello", and inside this directory, there is a file with the name "world". The path is a construct that allows us to relate an FS object with its location. So, the file's location, in this case, will be "/hello/world". The root has no name (empty string), and each level is separated by a /.
Mount Points
Yet another construct of FSes is mount points. It's a slightly complicated topic, so you need to read this part a bit slowly. So, you see, an FS works on a storage device. The storage device has to be formatted with the FS you want to use on it. Well, may be not ALL of the devices, if you consider partitions (opens in a new tab). However, for the purposes of this report, we assume you want to format the entire device.
Your OS has its own preferred and internally supported file system that houses the root of the entire machine's file system. This FS is given the title of "rootfs". Rootfs is the title given to any FS that the OS picks to represent its entire FS tree's root (/). This root is the big guy, the supreme mugwump (opens in a new tab). In the entire FS tree, nothing comes above it.
As it's a file system, it will undoubtedly have its own tree. An interesting thing to note is that it's not just the file systems that work with the VFS. VFS also works with device drivers, but it's slightly out of the scope of this report. Just assume that we can work with devices through their device drivers in the same way we would work with a file. In Unix, everything is a file (opens in a new tab).
So, your storage driver works with VFS and is represented symbolically as a file in your device tree. If it's a file, surely it must have a path right? Well, it does. Usually, Unix-based OSes put the device's device file in the directory /dev. The path means there is a dev directory inside the root. This directory also belongs to the rootfs. Inside this will be a large number of files (and directories). Each file represents a device connected to your machine. Some of them may be physically present, and some might be logical devices (again, out of the scope of this report).
Now, let's say, your NAND flash device connected to your machine is listed as the file /dev/nand, and you want to use mnemofs on it. Well, you can just mount it. What it means is that you tell the OS that this device is to be, or is already formatted with, mnemofs. Further, this also means you want to connect the file system that is present in this device to a preferred location in your rootfs.
Just like your rootfs has a root, so does the file system that's present in your storage device. Root is nothing but the top-most guy. That may be globally true in the case of rootfs's root, or locally true, in the case of roots of FSes formatted in the storage devices.
Mounting means attaching the local roots of the FSes in storage devices to locations in your rootfs tree. So, let's say, your local root has two directories a_local and b_local inside it. You mount your local root to the path /hi and provide the correct file system type. This means that these two directories can now be located by anyone or anything on your machine using the paths /hi/a_local and /hi/b_local respectively.
Now, this might be confusing. You might think, if the device is already located at /dev/nand, why can't I do something like /dev/nand/a_local? Now, that does make sense, but in Unix, there's a distinction between device files and file systems.
Firstly, device files are files and are the leaf nodes of the FS tree. They are not supposed to do the work of directories, and root nodes (local or global) are directories. Second, device files are an interface to the device driver of the storage device. You can use this driver to give it instructions on what to store where in its device. But, why should I do this? Doesn't this sound like the very thing file systems do? Yes. File systems, after being mounted, internally interact with your device's device driver (using this device file). What file systems do is arrange the logical constructs called files and directories that are stored inside your device at a convenient location in your rootfs upon mounting.
The location where a file system is mounted is called a mount point. When it comes to mounting, we call the file system instance that was formatted onto the device the "file system", and the type of file system as "file system type". For example, in the NAND device mentioned above, /hi is the mount point and represents the file system (ie. the file system instance formatted onto the device), while mnemofs is the file system type.
Do note that one FS type is not necessarily limited to one mount point. There can be multiple devices using the same FS type. As an FS developer, it is important to not have any "global variables", as each mount point is supposed to be independent of the other. All information needs to be instance-specific. How to do that? Well, patience. It will be explained later.
Mnemofs
Mnemofs is a file system built specifically to support NAND flashes for embedded systems using the Apache NuttX RTOS. Its components are a superblock, a master node, a journal, an LRU, and a block allocator (to name a few). These work in layers of abstraction, so I'll walk you through them one by one.
Due to the peculiarities of NAND flashes, we do not want to "update" a page. To update a page, we'll need to erase the entire block and write all of it (with the update) again. This will be very bad for block wear for multiple updates to the same block. Thus, we employ a tactic called Copy On Write (CoW). To update data in a file, we make a copy in memory, then update it, and then write the new information in a new place, and then update the location of this file.
Now, in its pure manner, Copy On Write cascades up to the root. Why? So, a file is updated by writing it in a new location. And the new location needs to be updated in its parent. Which again triggers CoW, and so on till it goes on upward in the FS tree till it reaches the local root (it might go on even further, but that's dependent on the rootfs).
This illustration will explain it well:
Let's assume the root (R) has a directory (A), which itself has a file (B).
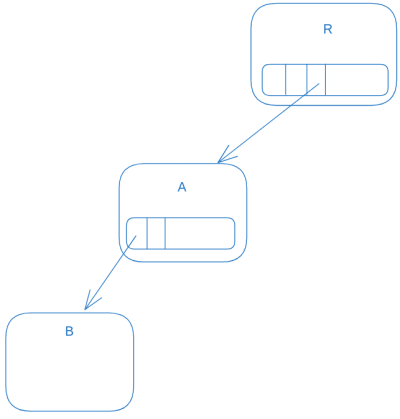
Let's assume we've updated file B to B'. This is how the entire process goes (in CoW's pure manner):
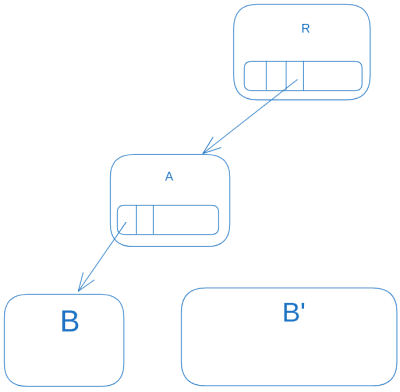
Then the parent is updated as A'.

And then finally we go further up till we update the root R to R'.

Then the old allocation are ready to be deleted.

For even one byte this goes up to the local root. A lot of writing for one byte right? Remember, the garbage left by CoW, ie. the pages that are old (and their data have been moved to another location), needs to be cleared when the page is to be used again. Mnemofs has measures to help mitigate this.
Also, file update seems to take a lot of memory if we have to copy the entire thing in memory, make updates, and save it to a new location right? Especially for large files? Well, we have measures to mitigate this as well.
Superblock
There are two versions of the superblock (SB). One that is formatted on the device, while the other that is present in memory. What is the difference? The former is pretty much useless for mnemofs, while mnemofs can't be used without the latter.
The on-flash SB is just a magic sequence of 8 bytes and some information about the device and is stored in the very first good block in the storage. The only purpose it serves is to be a very quick reference on whether the device is formatted or not. Other than that it contains no information that can't be obtained or derived from the device driver of the storage device. The on-flash SB, once formatted, is not updated. It's there to stay. It's pretty much symbolic and does not bring anything to the table.
The in-memory SB is stored in the private field of the driver and contains information about the device. Wait, but wasn't it the same as above? Yes. The difference is, here we need to query the information from the device only once, and keep it in memory as part of in-memory SB. From then, this stored information will be used instead of querying the device again and again (it's slower that way). It's useful in-memory, but it hardly serves any purpose if stored on the flash.
Block Allocator
First, let's get the dragon in the room out of the way. The block allocator. It's a fairly separate component of the file system. Another component asks for a page or a block, and this allocates one for it and gives them the page or block number to it. Kind of like a hotel receptionist.
Let's assume a hotel with all rooms identical. When a person is vacated, the room must be given a thorough cleaning before the next person is shifted in it. Also, assume the hotel cleaning staff will only thoroughly clean an entire floor at once, nothing less that than.
Let's expand on the process of room allotment in such a hypothetical hotel. It's best to allocate everything serially and cycle back to the beginning once you reach the end and continue. By the time you cycle back to a place, it may have been vacated since the last time you visited it and will be ready to be occupied again. Why is this the best? Because it ensures fairness to all the rooms and ensures the maximum wear difference of 1 between rooms when they will be cleaned.
Now, this can be applied to blocks and pages in our NAND flash. When pages are requested, the block allocator cycles through the available pages serially. It maintaines a bit mask to know which page is free or occupied by data.
Now, imagine a large group of people came, and demanded that they want to book an entire floor. Now the perfect sequential iteration plan has been thrown out of the window right? Well, the receptionist will just skip some rooms, keep them empty, and then allot them the nearest floor available. Now, a problem occurs. Your previous plan assumed no unoccupied room would be cleaned. Why wear down a room when it does not even need to be cleaned? So you change the meaning of the first bit mask to mean dirty rooms. And you keep another bit mask to know which rooms can be cleaned.
Once an entire floor is dirty and all the rooms on the floor can be cleaned, you call the cleaning crew. Until then, you only allocate pages that are cleaned. If a room is dirty and not ready to be cleaned, it means the resident is still occupying it. You can't just throw them out after all.
This is basically how the block allocator works in mnemofs. In a cyclical sequential manner, it keeps allocating clean pages or blocks that do not have to be erased. There are some limitations on when a page marks itself as ready to be erased, and some caveats to the entire erase operation, but we'll look into them later.
Suppose the receptionist dies one day, and a new guy takes over. This new guy doesn't know which room the receptionist had last allotted. So, if he starts allotting from the start, then the problem is that the rooms at the start will have more wear. Imagine if it's very common for receptionists to die. However unfortunate this incident will be, it will also pose a strong problem of wear misbalance in the hotel. Thus, each new receptionist will start from a random room instead of from the start.
The block allocator in mnemofs also starts from a random page every time it's initialized. The receptionist dying can be correlated with power loss in embedded systems, ie. the death of the block allocator, as it stays purely in memory. Volatile memory remember?
VFS Methods
Mnemofs exposes its own functions corresponding to every VFS-mandated FS method. For example, the one corresponding to open(2) (opens in a new tab) is the function mnemofs_open. Pretty intuitive right? Yeah. All sunshine in this section. Any VFS method is basically mnemofs_<method-name>.
These VFS methods usually have some functionalities related to traversing the directories, creating new FS objects, removing FS objects, moving FS objects, getting stats of FS objects, updating FS objects, and reading FS objects.
R/W Layer
This layer is very simple. You give a byte array 101101011010101110101110 (3 bytes) and tell it to store this on page 4, and it will either do it well, or return an error (either a bad block, or if the page is already written to, or if the device is not found, etc.), or it can also help you read the contents of a page.
It can also mark any block you want as a bad block, and even check if a block is bad or not.
Very simple stuff and this is the layer that works directly with the device driver of the storage device.
CTZ Layer
Mnemofs stores files and directories as Count Trailing Zero (CTZ) lists. These are a kind of backward skip list pioneered by littlefs (opens in a new tab), which follow a predictable pattern. Mnemofs doesn't follow this design word for word, but there are very minor changes, which do not bring any extra improvements to the table. CTZ lists are very good for updating, and especially appending, data to an existing file as governed by the as illustrated by the littlefs design specifications (opens in a new tab).
So, I'll be explaining the mnemofs version (which may overlap with the littlefs version in most ways). CTZ skip lists are made out of CTZ blocks. Each CTZ block in mnemofs takes up the space of one single page. The naming is kept like this to preserve the original nomenclature. Each CTZ block has a "data" section, and a "pointer" section. CTZ lists have a storage overhead of 2 bytes on average per CTZ block (again, as derived by the littlefs team), and this means that on average, each page will have 8 bytes of pointers in mnemofs, which I think is the best deal I've heard in quite a while. Most pages are usually more than 512 B, which makes the overhead at a maximum of 1.5%.
Formally, every CTZ block at index i (0-based indexing (opens in a new tab)) has a pointer for every whole number x such that i - 2^x >= 0 and i is divisible by 2^x. Examples will explain it much better. A CTZ block with index 6 will have pointers to 5 (6 - 1) and 4 (6 - 2). A CTZ block with index 4 will have pointers to 3 (4 - 1), 2 (4 - 2) and 0 (4 - 4). Also, a CTZ block with index 5 will have a pointer to 4 (5 - 1). In mnemofs, the pointer to i - 2^x lies in the byte range [page_start + page_size - (4 * (x + 1)), page_start + page_size - (4 * x)). Each pointer takes up 4 bytes of space, and it's created as a bottom-up approach, where the pointer to the immediate neighbour is the last, and the furthest neighbour's pointer appears the first out of the pointers.
So, apart from the area reserved for the pointers at the end of the page, the rest of the area at the front is for storing the data. This CTZ layer abstracts the data area and makes it seem like it's a single contiguous space for storage.
For example, if the page size is 128 bytes, then the first block (index 0) has 128 bytes of data area, and the second and third blocks have 124 and 120 bytes of data area respectively and so on. So, if you had to store, say, 255 bytes of data, the layer just takes in the array you want to store, and the CTZ list, and this layer will split into (128 + 124 + 3) bytes. This means that the data area of the first two blocks will be full, while the third block (index 2) will have only 3 bytes at the front.
This abstraction is also applicable for reading data from the CTZ list. Everything happens under the hood.
Littlefs developers have derived a very convenient method of finding out the CTZ block index and CTZ block offset (ie. page offset in mnemofs) from the data offset (ie. offset into the data area, assuming it to be a contiguous space). They've also demonstrated how a CTZ list can be identified by just using the location (page number) of the last CTZ block and the index number of the last CTZ block.
Over that CTZ lists are quite suitable for updates in CoW environments, as shown by the design document as well. The part before the update is kept the same, and the later part is updated and written to a new location.
Files and Directories
Files and directories are represented by CTZ lists. While the file contains only the data included in the file, the directories are basically files that contain the list of FS objects inside them. We call the entries in this list as directory entries or direntries. These direntries contain metadata about the FS object they point to name, size, location, time created, time modified, etc.
Journal
Mnemofs uses a journal. Combining the CoW tactic and a journal will allow mnemofs to be resilient to power losses. How? Well, let me explain what a journal does.
So, let's say, we make a change to a file. This file now has a new location. This, as discussed above, goes on to cascade to the local root. Suppose, in the middle of the copy, there's a power loss. The entire work of updating needs to be done again. Instead what we do is that we just write the new location of the file as a log to the journal. So, when we want to get the location of the file, we first traverse the FS tree to get the old location, then traverse the journal to get the new location.
This also saves from updating the parent immediately, since it doesn't need to be updated in the parent as long as the log of the update remains in the journal. Each log is appended by a checksum of it to ensure that the entire log was fully written, and that there were no power losses in between.
The journal is a singly linked list made out of entire blocks, and each log and its checksum take up an entire page (for now). After the journal is full or above a certain limit, it will be flushed to empty it, but we'll discuss this later.
But, in a traditional linked list, each node has the pointer to the next node. However, we've established that journal logs are one page in size. Also, the smallest writable size is a page. Since we're preallocating the journal blocks, we need a place to store their location. Traditional way would lead to a lot of wastage of space. Thus, the journal starts with a unique magic sequence, followed by the number of blocks it has (excluding master blocks), and then writes an array of all block numbers of blocks in the journal.
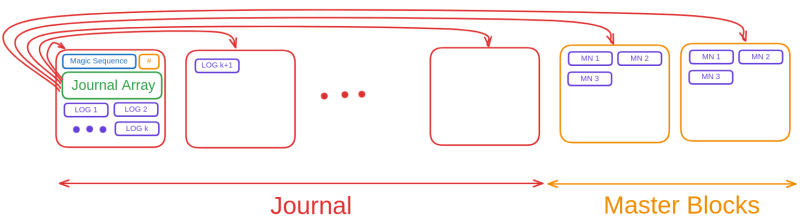
Master Node and Journal Flushing
Mnemofs has a component called a master node. This master node basically points to the root of the file system. This allows the root to be treated like any other file as far as space allocation goes.
Where does the master node live? In a very special location. You see, the journal is made out of n + 2 blocks, such that the first n blocks are the only blocks that are in charge of storing the logs. The last two blocks are called the master blocks. The two master blocks are identical to each other and act as each others' backups, given that the master node allows you to make sense out of the ones and zeroes stored on your device. So, master nodes are stored in the master blocks, not too unlike how logs are stored. The entire information about the root is stored along with a checksum and a timestamp. These are serially stored, so the last valid log entry points to the actual current master node.
When a journal is flushed, the entire local FS tree is updated. The update of a child means storing the updated location in the parent, which also means the parent is getting updated as well, and so on till the root has another updated copy of the root. Once we get the location of the new root, we know our flush operation has been completed. Since updating the root also means the master node is updated, a corresponding new entry is appended (opens in a new tab) in both master blocks. This new entry is a new master node.
We make the journal's blocks follow the same wear rules as the other blocks. The moment it is to be erased, the block is given back to the block allocator as a "to-be erased block", and it is only used again (after erase) after ensuring every other block in the entire device is used once, but more on this later. So, every time a journal is flushed, it has to "move" to a new location.
Each time a journal is updated, a new master node gets written. Since a block has multiple pages, and a master node takes up one page, then there can be a pages_per_block number of master node entries, and thus a pages_per_block number of journal flushes, before the master blocks are full. Thus, the first n blocks of the journal move much more than the last two blocks. Upon the pages_per_block + 1th flush all of the n + 2 blocks are flushed, and thus the entire journal moves in this case.
Least Recently Used Cache
Well, first of all, my naming sense is bad. It's the Least Recently Used Cache. You can call it a cache, as it's like a twin to it. But in the case of mnemofs, it doesn't provide any benefit of being a cache, as far as read times are concerned. So we'll just call it the LRU.
Why doesn't it provide any benefit of being a cache? Well, we need to discuss what it does first. The LRU's job is to effectively store all the changes a user requests in memory. Then, say for a single file, when a lot of these changes have been stored, they are applied to the flash together. So, let's say we wait for n operations from the user before emptying the changes of a file stored in LRU. That would mark it as one operation to the flash for every n operations. We can have the entire size of the LRU to be configurable, to allow users to pick their own sweet balance between memory consumption and flash wear reduction.
We still haven't answered the initial question yet. But before that, we also need to look into the structure of the LRU. The LRU is made out of something called a kernel list (opens in a new tab). For the uninterest people, it's simply a clever way to write circular doubly linked lists. The kernel list in LRU contains several nodes. Each node represents an FS object, be it a file or a directory. Now, each node itself has a kernel list as well. This list is made out of what mnemofs calls deltas. Each delta is an operation by the user. To the person who takes pain to understand the VFS methods, it is clear that the VFS methods, at their base, deal with some fundamental operations on FS objects. Namely, either reading, updating (and writing), or deleting some bytes.
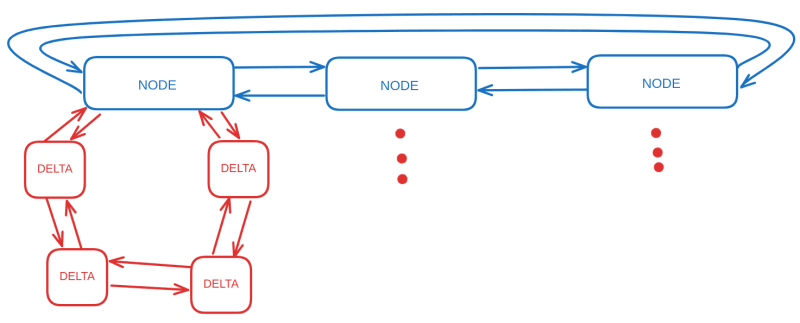
Mnemofs has some further restrictions on this, to allow the usage of this LRU to be a bit simpler. When it comes to updating, VFS methods can ask you to put m bytes in place of n bytes. However, the way mnemofs works, we force this to follow the condition m == n (we'll discuss about this a bit later). If you're writing to a file, it will be replacing n bytes of 0-byte filled data, with n bytes of actual data, and so on. And then there's the delete operation, where we remove n bytes of data. Both operations start at a specific offset, which menmofs calls a "data offset" (as it's offset inside the data stored in the CTZ lists).
When an LRU receives a delta for a specific node, it will bump the node from wherever it is, to the start of the LRU. This way, the last node is always the least recently used node. When the LRU becomes full, and wants to add a new node, it will pop out the last node before adding the new node. This pop will follow with the deltas being actually written to the flash, and then having their corresponding log in the journal.
Now, finally, the answer to the initial question. Well, thanks for waiting this long, but I'm afraid you'll have to wait a bit more! I'll have to explain the entire process through which all components work together to be able to make you understand, so please bear with me.
Entire process
Well, the user makes a syscall (opens in a new tab) (directly or indirectly) to do something with a file or a directory. This is then transferred to the VFS, who find the right file system to deal with the request. How? Well, the path provided by the user, and the mount points of file systems help in this. So, let's say we're lucky the user refers to mnemofs.
Mnemofs then deals with the request appropriately. Let's say, it deals with reading 5 bytes from an offset of 10 in the file. What file the user is referring to needs to be found. First, the current master node is consulted to get the location of the root. Once we get the root, we traverse the directory entries (direntries) in it to find the suitable FS object that the path refers to after the root, and so on, till we either reach the intended path, or give an error of not finding the desired FS object.
What we got here might be an old location for the intended FS object, so we traverse through the journal to find the newly updated location. Once we get the new location, we read the data stored in the list. However, this data might be old as well, as the LRU contains the latest data. So, we apply the changes to the CTZ list from the LRU. We do this cleverly to allow the changes to be applied in memory, and in chunks, to set an upper bound on the memory usage.
Thus, we get the updated information. Since the LRU comes last in this process, that's why it doesn't behave like a cache per se.
Let's say we want to delete some data. Most of the previous process will be the same. In this case, we just add the fact that we want to delete n bytes from m offset in the node corresponding to this file as a delta, and the node will be bumped to be at the start of the LRU. If the node gets full, and another delta is to be added, the node will be emptied of all deltas, which means, they will be written to the flash. Similarly, when the LRU gets full of nodes, and another node is to be added, the last node is popped, and written to the flash. When the changes are clubbed together and written to the flash, their new location is updated in the journal as a log, followed by their checksum.
Now, if the journal is above a certain limit (usually 50% full), the journal is flushed. The file system enters a state of flush. All the changes in the journal are written. However, this will cause changes in their parents, and these changes will go through the same process that all changes do in mnemofs. Then the flush will be repeated again, and again. Do note that the journal has not been erased yet. The reason why we flush the journal when it reaches a certain limit, is to keep space for the logs of their parents and ancestors during the entire flush operation. So, this way, when we finally reach to the top of the local FS tree, the new root is written, and a corresponding new master node is written.
Once this master node is written, the entire flush operation is basically complete. We just wipe the entire journal clean. We do not need the logs anymore. Why? Once an FS object's latest log is written, all the logs of its children are useless, as the new location already is updated with the latest locations of its descendants. As the local root is the highest you can go in the local FS tree, once its log is written (which is the master node entry), all other logs are not required, and can be erased freely.
Now, sometimes, the master nodes might be full, in which case a new journal and new master blocks are allocated space, and then the new master node is written to it. The master node also contains the location of the journal, and thus, this new journal will instantly become the new journal once the master node is written to it, and the old journal and its master blocks are given back to the block allocator to be erased.
Now, till the new master node is not written, none of the pages related to old locations should be erased. Why? Imagine we have a power loss, and we want to retrieve the old state of the file system, only to find your dear block allocator has erased them thinking they won't be needing that. Turns out you do need that don't you? So, once the new master node is written, only then will any erase operations happen. During the flush operation, all the pages containing old data mark themselves as "to-be erased", however, only when the new master node is written, will the block allocator scan through all the pages that want to be erased to check for entire blocks that want to be erased, and then erase them.
My Pull Requests
My contribution was to implement mnemofs to a working state. It's not feature complete yet, however, it's very close to being so. These were my contributions related to the project and tools related to my work on this project:
- #11806 drivers/mtd/mtd_nandram: Adds virtual NAND Flash simulator (opens in a new tab)
- #12396 fs/mnemofs: Adds mnemofs and mnemofs journal (opens in a new tab)
- #12658 fs/mnemofs: Setup and VFS methods (opens in a new tab)
- #12661 fs/mnemofs: Add Block Allocator (opens in a new tab)
- #12668 fs/mnemofs: Add parent iterator and path methods. (opens in a new tab)
- #12680 fs/mnemofs: Add LRU and CTZ methods (opens in a new tab)
- #12683 fs/mnemofs: Add journal methods. (opens in a new tab)
- #12701 fs/mnemofs: Add master node and r/w methods (opens in a new tab)
- #12808 fs/mnemofs: Refactoring path logic, direntry size bug fix, open free bug fix (opens in a new tab)
- #12937 fs/mnemofs: Fix journal log rw issue, rw size issue (opens in a new tab)
- #12943 fs/mnemofs: Autoformat (opens in a new tab)
- #13147 docs/fs/mnemofs: Update new design and NAND flash structure (opens in a new tab)
Further, before GSoC, I've made some contributions while getting started with the codebase:
- #11647 fs/vfat: Fix typo in the macro DIRSEC_BYTENDX (opens in a new tab)
- #11656 docs/fs/vfat: Improve VFAT documentation (opens in a new tab)
- #11730 fs: Add VFS docs (opens in a new tab)
Conclusion
I've had a very great time contributing to Apache NuttX, and I plan to keep continuing my contributions to both mnemofs and the entire Apache NuttX codebase as well. I had the fortune of working under a great mentor, Alan (opens in a new tab), along with the entire (very supportive) Apache NuttX community. I can not thank them enough for giving me the chance and considering me as a suitable contributor for GSoC '24 for this ambitious project. Further, I've had the pleasure of being at the receiving end of the waterfall of knowledge that's written by the littlefs team in their design document (opens in a new tab).
Last but not least, I've had the fortune of having the immense support of my parents, friends, co-contributor Rushabh, and co-workers in this entire journey, without whom I could not have done it.
Thank you to you too for reading this far.
⌂ Home
MIT 2024 © resyfer.